

�����Z��ģ���������ı����䡢ģ�M���Ԓ�ͽ�Q���W���}������F��ɫ���@Ȼ�ǽ����AI�lչ���ܚgӭ���I��֮һ��Ȼ�����@�N�����Z��ģ�Ͳ��H�����Լ������к����ݣ�߀����ͨ�^���Α��ó��������
оƬ��ُ�W��ע�����χ������ڙ�IC�����̬F؛�YԴ��оƬ��挍�r��ԃ���ИI�r���������ُ����ICоƬ�����Ȍ��IоƬ��ُƽ�_��
��Փ�ϣ�������˵ą��c��ԓ�����ڽ�Q���}��Ȼ���������Z��ģ�͵���Ӗ��Ҫ�����Ĕ�����Ӌ��������������Ȼֻ�Ǵ��ͿƼ���˾�Ī����Ŀ���ڌW�g�硢����W�Һ�����ƌW�ҵȸ��V����Ⱥ�w�У�ֻ�����^�ߓ����˹����ܞE�á�
�����Ž������ε�Ψһ�������ǘO������Meta AI���ն��̠���Ƥ�Z��Joelle Pineau���f�����ؕr�g5��3�գ�Meta AI����1750�|�����Ĵ��Z��ģ���_��OPT-175B��Open Pretrained Transformer��OPT����
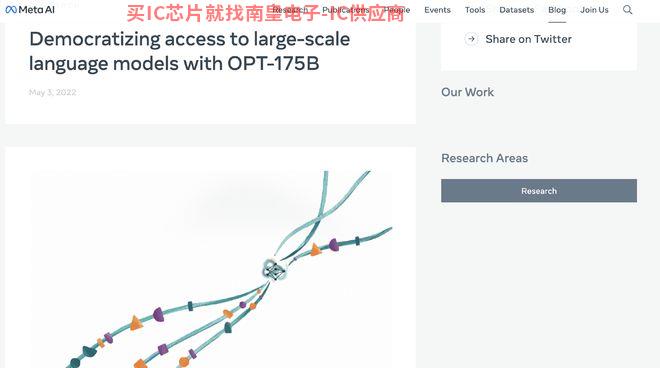
�@�����ͿƼ���˾���f��ǰ��δ�еġ���ʹ�ڴ��Z��ģ�͵Ěvʷ�ϣ��@Ҳ�ǵ�һ�κ��o��������¶���е��AӖ��ģ�͡�Ӗ�����a��ʹ�ô��a��
�҂��е��S���˶��Ǵ�W���о��ˆT��Ƥ�Z�f���҂�֪������W���ИI�ڽ����@Щģʽ�������ϴ��������@�IJ�ࡣ�����@���о��ˆTӑՓ�@헼��g�ĺ�̎����ϣ�����������м��о������Ĺ������������������ڴ˻��A�Ͻ������������J�飬��������˅��c�M��r��ͻ�ƾ͕�����،��F��
OPT�Z��ģ���мs��1750�|������(�@Щ�������W�j��Ӗ���^���п����{���ą���)OpenAI�_���Ե��W�jGPT-3Ҏģ������ͬ���и��M����GPT-�Ƿ��������Ͳ��ɱ����ȱ�ݡ�
�@�ǽ��^�����OӋ�ģ�Ƥ�Z�fOPT���]�Z���΄յĜʴ_�Ժ��к���GPT-3��ƥ�䡣OPT���о��ˆT�ṩ��Ƶ��Z��ģ���M���о���
OpenAI�ܽ^�ˌ�Meta�uՓ����
OpenAI�ȸ��ĸ��˾����̽�����������aƷ��ʹ�ô����Z��ģ�ͣ���Ҳ��ȱ�����ȶ��ܵ����u���ȸ����˹����܂����о��T��������S�ࠎ�hTimnit Gebru�������l��һƪ�P�ڹȸ讔�r�Z��ϵ�y��Փ�ģ�����ܕ��ľWվ�όW������ƫҊ�ͳ��Փ�ģ�����������һ�������l���о��ĆT����
��ô��Meta��ʲôҪ�@������MetaҲ�����ᵽĘ����Ę��Instagram�Ƽ���˾������㷨����ԭ�������}�����ĿƼ���˾������㷨����ԭ����
������ʡ�����Ƽ��uՓ��Meta���ò�ͬ������һ����Ҫԭ����Ƥ�Z���˶����һֱ�ڴ��M�˹������аl�����ȡ�
�ں��ČW�g���h�l�����о������У�Ƥ�ZҪ���о��ˆT�ύ�������a�Լ�����M�Ќ���Ԕ����Ϣ�ͽY��������2017�����Meta�����r��Facebook���˹����܌����һֱ�����@�N�Ļ���
��Meta���_�ſƌW�ij��Z�l�����@�﹤����Ƥ�Z�f��
�����a�⣬Meta�_�l��־Ҳ�����ˡ���־�����F꠳ɆT��������Ӗ���ճ�����:��Ό������ӵ�ģ���У��Լ��Εr����Ч�͟oЧ����100��퓵ĹPӛ�У��о��ˆTӛ���2021��10����2022��1�³��m�\�е�������Ӗ���^���е�ÿһ���e�`��������ILSI�����؆���
˹̹����W���Aģ���о���������Percy Liang����ģ�͵��_�ų̶ȿ��Y���Ă��ӴΣ�
��һ��Փ���_�ţ��C��һЩ�뷨�Ŀ����ԣ����ṩ����˼·���ڶ���API�_�����S�о��ˆT̽�����u���F��ģ�͵������������������������ƣ���ƫҊ����������ģ�͙��غ���Ӗ�������_�����S�о��ˆT���M�F��ģ�ͣ��_�l������Ŀɽ�ጼ��g����Ч���{�������о��ˆT���õ��˽���Ӗ������ģ���О��е����ã����Č��_�ŵ�Ӌ���������S�о��ˆT�Lԇ�µ�ϵ�y�Y������ӖĿ�˺��^�̡��������ɣ����ڲ�ͬ�I���_�l�µ�ģ�͡�
���ߌӴε��_�ſ����о����Pע����ӴεĆ��}��ͬ�r����������L�U��Percy Liang���_ָ���@һ�c��
Meta���@�N�̶��ϣ��_Դ������Z��ģ����һ헷dz���đ�Ĵ�ʩ�����ܕ��a��Ŀǰ�o��������L�U��OpenAI���ڲ��l��GPT-3��ǰ��GPT-�o����ԭ��
�Ҳ��ܸ��V���@��ģ�Ͳ������������µ��L�U��Ƥ�Z�g���˃H�H�����̫Σ�U�ˣ����Բ���ԓ�l��ģ�͵��뷨�����f���������@Щģ�͵����c�����@����һ�N�о��đB��
��������ʡ�����Ƽ��uՓ�����˹����܂����о��T�����������`�����О�ʄt���ȸ��͡����Р���Margaret Mitchell���J�飬OPT�l����һ헷e�O�Ĵ�ʩ�������J�����������ġ��������Z��ģ���Ƿ��^��������Ĝyԇ�����AҊ�ĺ�̎�Ƿ��^����AҊ��Σ������α������@���^���Юa���e�`����Ϣ�����߷N�����x�ͅ���Ů�Ե��Z�ԣ���
���������Aʢ�D��W��Ӌ���Z�ԌW�ҡ�M�����£�Emily M.Bender�������ڹȸ������c���Р������о������������̎�흓�ڵ�Σ���������κΙC���W�����g�L�U�������P�I�����ض����������M���u����̽�������磬ԓϵ�y���Á���ʲô�ģ��l��ʹ������ϵ�yݔ������γʬF�o������
����Ƥ�Z���f���@Щ���n��ԓͨ�^����Ĺ��_ӑՓ����Q�������ǜp�ٜ�ͨ��������ص��˂���ʲô�ӵČ�Ԓ�в�ͬ�Ŀ������˹������nj�Ԓ��һ���֣�Ƥ�Z��ϣ���Z��ģ�����f��ÿ���˶�ͬ���Ԓ�����҂���ԓ���̎���أ�Ҳ�����f����ӑՓ�^���� �e�˵�����



















- ��������ȫ�ȼ��gȫ���x�ܷ���������I
- Meta ���s�ɱ�Ӱ푹���˾�C������܇�����̴���ÆT
- �l�ͺ��շ�Ҏ�������ע�ԏ��N�ğo�˙C����ID,���F�h�̴_�J
- ���_˹���Ƴ����ȑ����̵꣬�����ǹȸ葪���̵�
- �������_�����S�������罛��Փ��ȫ������W�j
- ̩�팍�y001:���ø��������������ƽⶶ������
- Bournsȫ�´����PTVS���O�� �߂�20kA��ӿ����͵�λ늉�̎������
- ���ڴ�����ƽ���F���Ƴ�Intel�Ƅ����ܳ������aƷ
- ���_˹����Ʒ�ƹPӛ����288nm M1̎���� ������s���u1.3�f
- ���피��ƄӼ��g�ӳ֣�����5ϵ�д���˵���ͻ�����Α��w�
- imec��С�ŵ����t��֪оƬ ���ģ�M�����D�QЧ��
- ���ȴ惦оƬȡ��ͻ�ƣ��L���惦192���W���͘ӣ��AӋ������a
